
When we started to develop Slang in early 2018, the focus was to test whether our stream-based paradigm is suitable for general programming. We took a completely new path and implemented a concept that has not been explored yet. By this time, we can say that the path we took looks very promising and allows for fast and flexible development in different scenarios.
System integration particularly benefits from high development speed, flexibility and ease of use. However, another important concern in this context is performance and scalability. To investigate where Slang stands in these matters, we benchmarked its stream processing capabilities.
Streaming benchmark
We used the Yahoo Streaming Benchmark to see how it compares to Apache Storm and Apache Spark. They are both stream processing engines being used in production environments and can serve as a reference for production readiness in terms of performance.
Simply speaking, the Streaming Benchmark uses a Kafka broker as a source for events and a Redis server as sink for aggregated data.
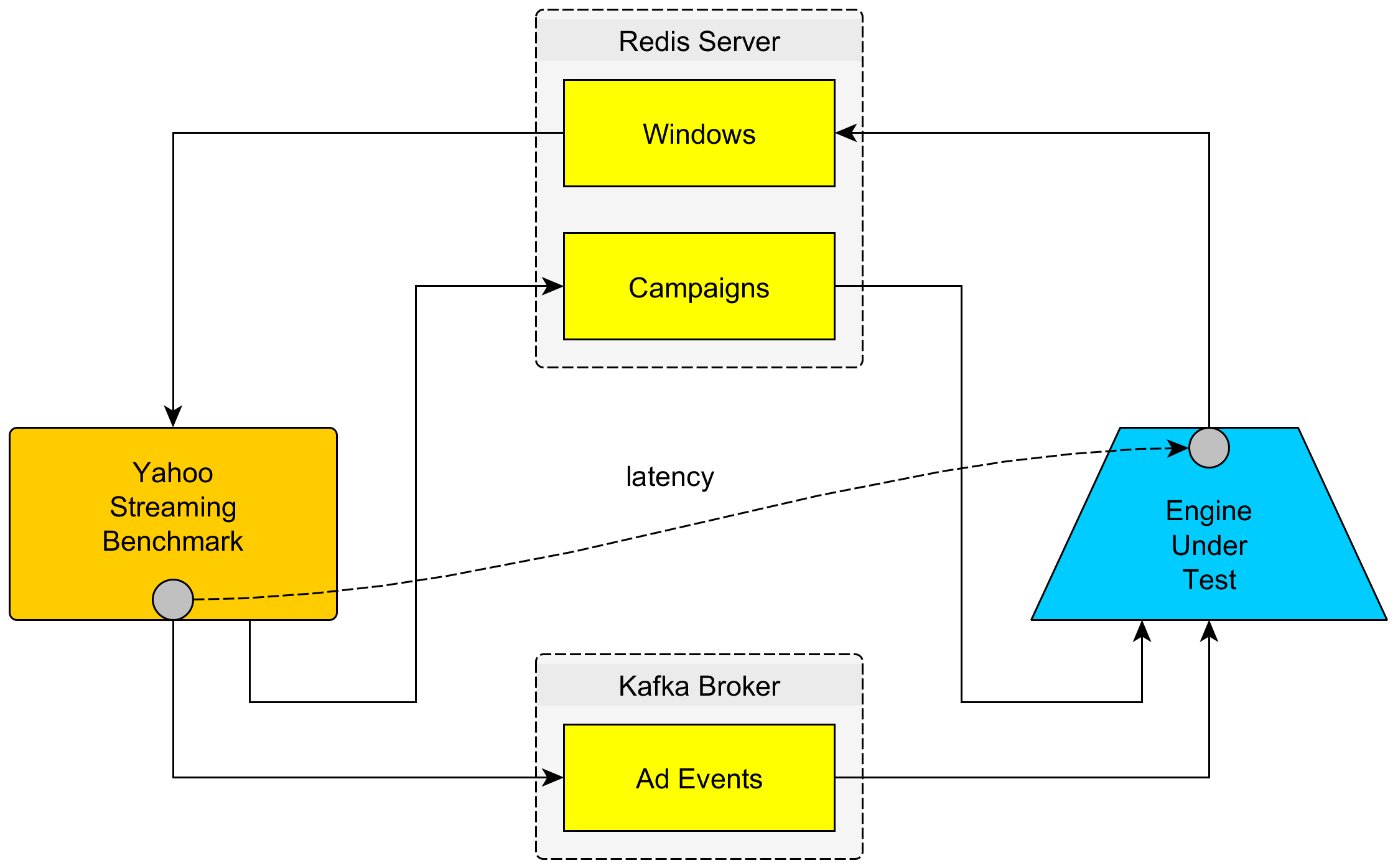
It pushes ad events consisting of an ad ID, a timestamp and some other fields as JSON string. The data stream then has to undergo these steps:
- The stream of JSON event objects must be deserialized
- It must be filtered for events of type “view”
- Then, the campaign to which the event belongs must be fetched from the Redis server
All events belonging to the same campaign and time window of 10 seconds are counted and written back to the Redis server. This is how the Slang implementation looks like:
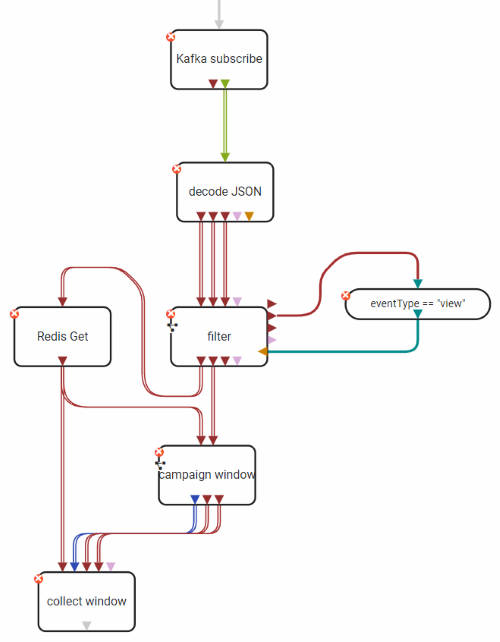
You can find the operators together with an adapted fork of the streaming benchmark in a separate GitHub repository.
Measurements
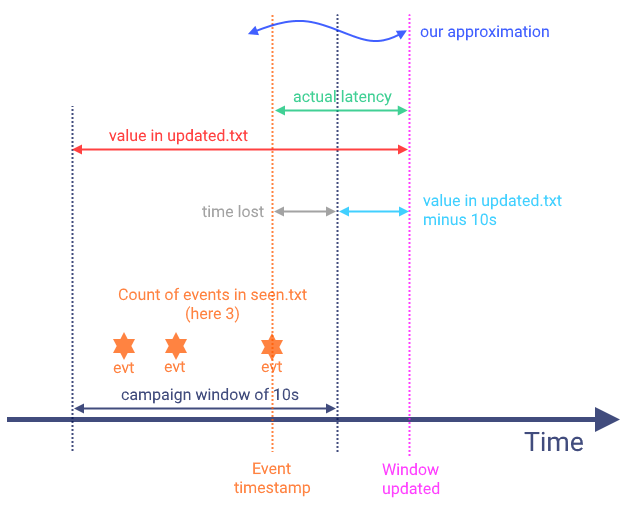
The streaming framework creates two files, updated.txt and seen.txt.
The first contains the latency and the second contains the number of ads per campaign and time window.
During the benchmarks we ran, about 240,000 events have been aggregated into 2,400 windows within 4 minutes (1,000
events per second) on a single node (16 GB / 6 CPUs droplet from DigitalOcean).
We also have run tests with 5,000 events per second without detecting significant changes in latency.
To make sense of the values there we need some further calculations. I won't go into more detail here. If you are interested, feel free to check this GitHub issue. The general idea is illustrated in the figure below.
Results
The results are shown in the following diagram.
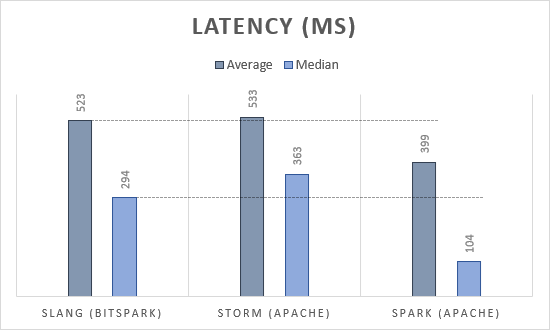
As you can see, Slang is slightly faster than Apache Storm but slower than Apache Spark. We have mainly focused on usability and ease of use with Slang. There is still much potential for optimization of course.
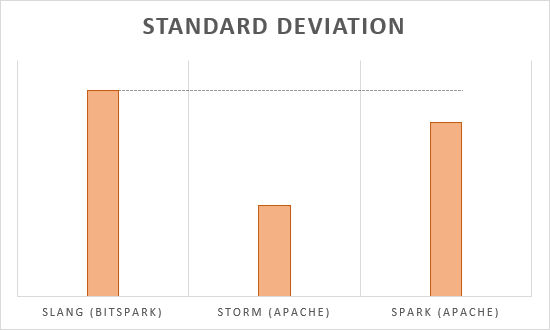
The standard deviation of the latency is comparably high due to the high amount of co-routines (go-routines) involved and the non-determinism in scheduling that comes therewith.
Still, we are quite happy and admittedly surprised that apparently Slang can already compete with stream processing systems being used in production environments. We cannot guarantee strict time constraints at this point, but if needed our Slang runner can be extended with such capabilities.
